4 Months to 2 Weeks: What I Learned Rebuilding My App with Claude Code
I’ve just rebuilt my macOS app Flowcus from the ground up.
The v1 Swift app took 4 months to build last year using Claude Code and Sonnet 3.7. The revamped v2 Tauri/TypeScript app took 2 weeks with Opus 4.5 and 4.6 and it’s significantly more capable.
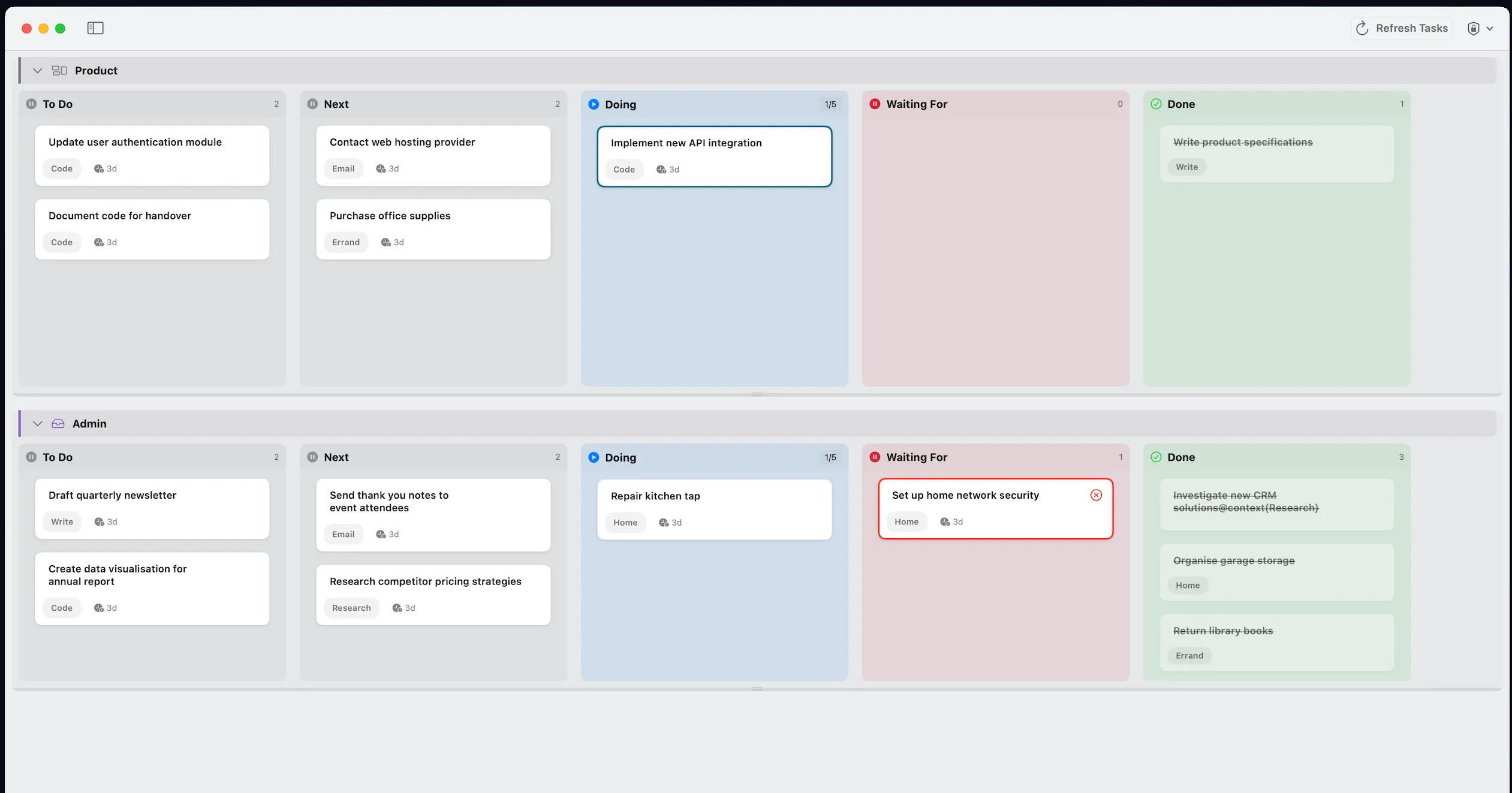
Flowcus is a task management app that goes beyond the standard “list of things to do.” It integrates with OmniFocus, TaskPaper and Things, visualises your work on a Kanban board and adds intelligent features that traditional task managers don’t offer. It’s my attempt to apply lean thinking to personal productivity and offers capabilities missing from other task managers. For instance:
- Radar surfaces important tasks
- Ghost Detection flags vague tasks and spots work moving backwards in your process
- Sidekick integrates with a local or remote LLMs directly from the app, so you can get AI help without leaving the board
- and, as all product promises go, much, much more
What Changed Between v1 and v2
Version 1 worked but it was a mess of code that made maintaining and updating a hassle. I reviewed most commits and manually fixed issues or made improvements when Claude got things wrong.
Version 2 works really well and I use the app daily. I reviewed the code early on but more recently I haven’t felt the need to. There are over 2,000 tests (added via a custom red/green TDD skill) that I’ve glanced at but nothing more.
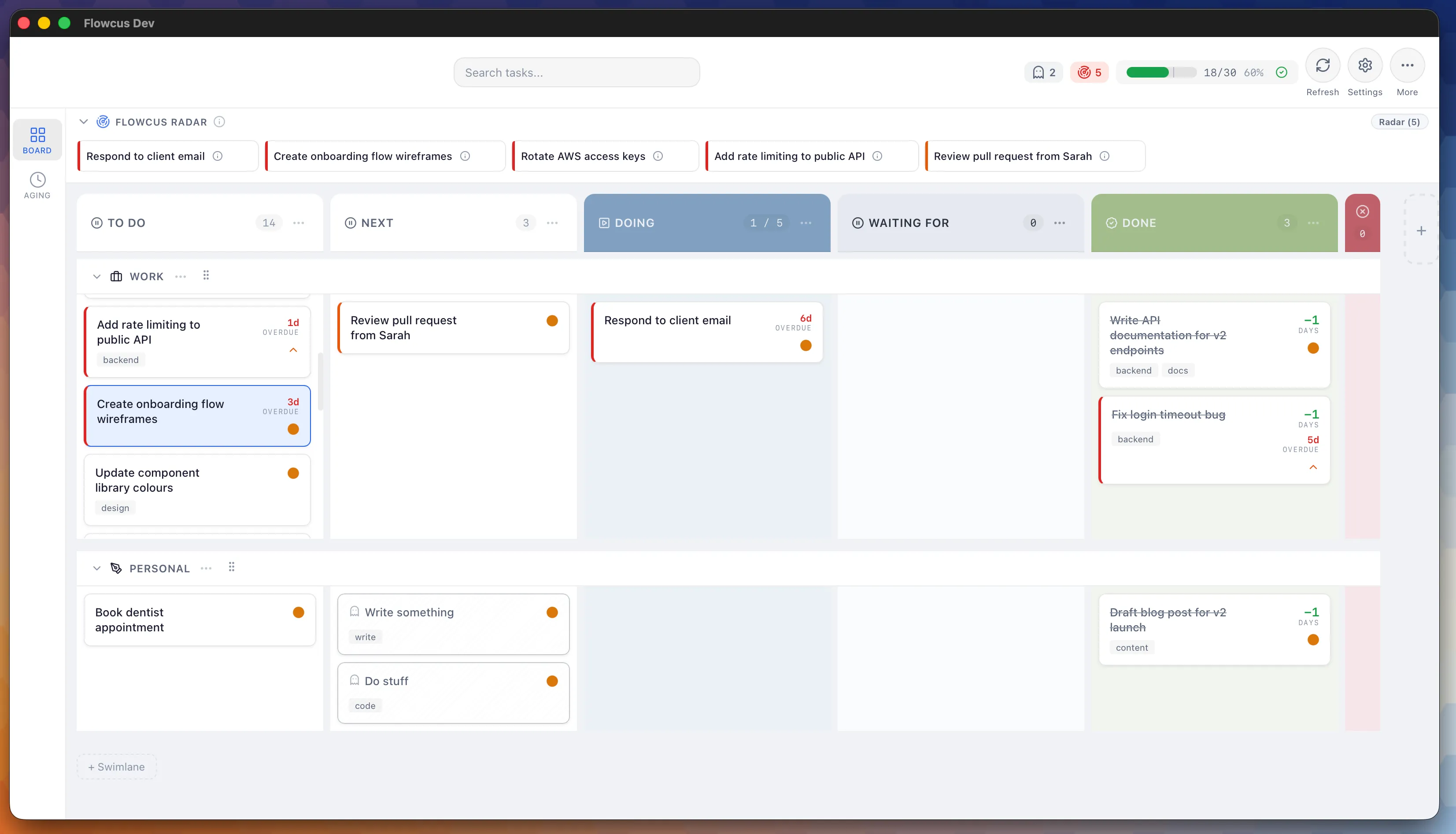
This is making me think a bit. I have a shipping application with thousands of tests that I haven’t meaningfully read and the app works as specified. It raises an uncomfortable question about what “understanding the codebase” means when an agent wrote most of it. For now, as a black box exercise, the answer seems to be: it doesn’t matter as much as I thought but there’s a nagging feeling that I’m not quite used to.
What Made the Difference
The jump from Sonnet 3.7 to Opus 4.5/4.6 clearly but the model alone doesn’t explain the time difference compression. The real shift came from investing in the layers around it: custom skills to enforce discipline, Beads for persistent issue tracking and regular feedback loops to encode patterns into permanent rules.
Custom Skills
I created reusable workflows as markdown files, split into two categories.
For discipline:
proposeforces the agent to present competing implementation approaches before writing a single line of codebugfixenforces systematic TDD-based diagnosis rather than speculative fixesspecturns vague feature ideas into implementation-ready specifications by probing the codebase for context
For delivery:
workhelps the agent complete work autonomously given a specific issue ID or instructionsplitbreaks down complex work into discrete, manageable pieces — smaller work means increased chances of the agent getting it right first timebatch-polishworks through groups of small UI refinements as a single efficient pass
Additionally, Anthropic’s frontend-design skill generated UI wireframes, helping me pick styles and components before committing to a decision.
Beads
Beads gave Claude persistent memory across sessions: full visibility into open work, dependencies and blockers, recoverable with a single command. It replaced scattered markdown planning files with effortless, structured issue capture. I also built beads-dashboard, a local lean metrics dashboard providing visibility into lead time, throughput and other continuous improvement metrics.
Insights
The Claude Code /insights tool analysed my conversation history to highlight recurring agent mistakes. I encoded those patterns as permanent rules in CLAUDE.md to avoid correcting the same errors repeatedly.
What Worked
The agent combined with skills and persistence is a much more intuitive and productive approach than raw prompting. Features and ideas I’d previously discounted due to complexity are now unlocked. Time to build from prototype to shipping feature has drastically reduced.
One workflow I didn’t expect to be so effective: I built roughly 25% of major features by triggering remote Claude Code sessions overnight. I’d assign a bead, kick off the work skill before bed and review a completed branch the next morning. Not every session produced mergeable work, but enough did that it became a reliable part of the rhythm.
What Didn’t
Claude confidently pursues wrong root causes and sometimes misses system-wide impact. A persistence bug is a good example: Claude’s first fix targeted a type comparison issue, but the actual bug was a startup race condition. The pattern of fixing the visible symptom rather than the underlying cause repeated across multiple sessions.
The other thing I’ve noticed is harder to articulate. The whole process feels a bit too slot machine-y for my liking. There’s a pull: “just one more change”, “just one more feature” driven by how fast results appear rather than whether the next change is actually the most important thing to do. The dopamine hit of shipping something in an hour that would have taken days creates a near-compulsion to keep prompting. I’m conscious of it but it’s a dynamic that I wasn’t expecting.
Why This Matters
Building Flowcus v2 has rekindled my enjoyment of building and creating software. That’s not a small thing. There’s a real satisfaction in taking a problem you understand deeply — the gap between how you want a productivity tool to work and how existing ones actually do — and building a shipping application that closes it. For years, the implementation barrier meant those ideas stayed as sketches and notes. Now they’re real.
Flowcus is free and available at getflowcus.app. The open-source beads-dashboard is at github.com/rhydlewis/beads-dashboard.